A common design pattern involves creating a wrapper around a commercial providers language models using their APIs and a framework like LangChain or LlamaIndex. Providers include OpenAI (GPT-Ns), Google (Gemini/Gemma), Cohere, Anthropic (Claude), etc. Fundamentally, this is a reasonable approach if the following are true:
- The task’s value justifies the cost of employing closed-source models at scale.
- The model provides satisfactory results without requiring fine-tuning.
- Your domain permits sharing data with these providers to enhance their models.
- Your organization accepts the reduced transparency associated with closed-source commercial models.
The deliberate choice being made for this Miata.Bot project is to not use any commercial GenAI models or tools, in order to retain the flexibility (to swap LMs and frameworks) and cost-effectiveness that comes from using open-source models and tools.
Language Model Choice
While there are a number of open-source LMs to choose from (crowd-sourced list), some considerations for selecing a LM include - size (2B | 7B | 70B), who its from (Meta | Mistral | DataBricks etc.), performance on your task, etc. While there’s no rubric that I’m aware of for selecting a LM, the choice does depend the context of your task and your technical abilities, amongst other factors.
For this project - the plan is to test fine-tuning Meta’s Llama3 8B language model. Some reasons for selecting this LM are:
- Llama3 is an open-source model, meaning it can be downloaded, fine-tuned and used for commercial and non-commercial purposes with some minor limitations.
- The model includes machine-learning model code, trained model weights, inference-enabling code, training-enabling code, fine-tuning enabling code and other elements distributed by Meta at https://llama.meta.com/llama-downloads.
- 8B parameters seems to be the sweet spot in terms of performance vs size at least for this generation of LMs.
- Amongst open-source models with 7-8 Billion parameters - the choice seems to be mostly between Llama3 8B and Mistral 7B, and Llama3 seems to outperform Mistral 7B out of the box (source).
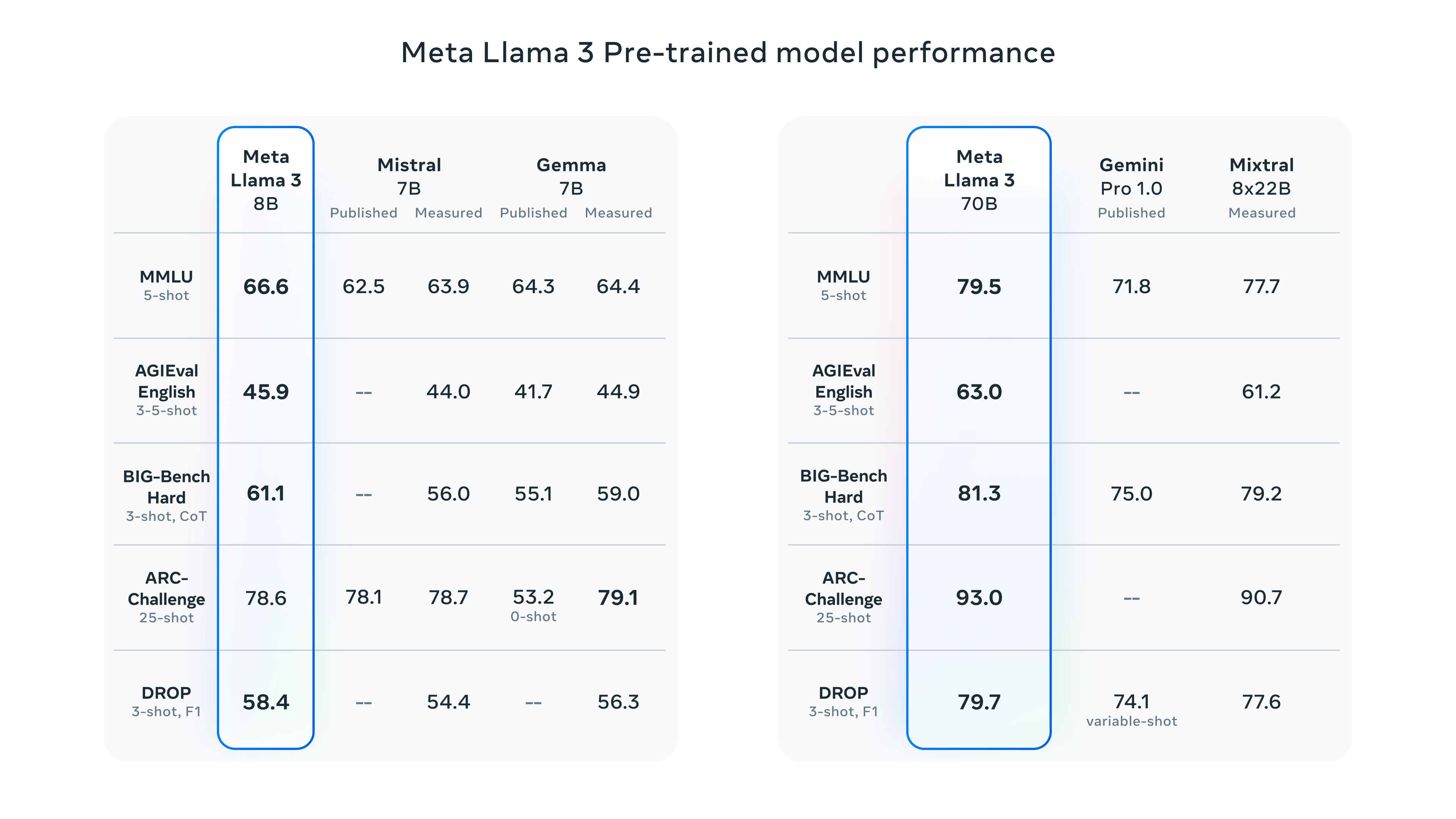
- There’s a lot of data out there about the effect quantization on Llama3 performance - quantization enables a reduction in size of a LM without decreasing performance.
GenAI / LM frameworks
Before going down the path of using the different approaches for fine-tuning a LM or building a LM based application, it’s useful to review available Gen-AI / LM frameworks and get a sense of their capabilities. This section contains the frameworks I’ve heard about or come across most often when keeping up-to-date in this space.
LangChain (+)
LangChain provides high level abstractions for NLP and GenAI tools. In practice, this means that instead of using a number of different Python packages for different bits of functionality, you can use LangChain as a common wrapper for a whole range of functions, such as:
- Vector-stores - interfacing with vector storage and search engines such as PineCone, Croma, etc.
- Chatbots - high level API to build a stateful chatbot using prompt-templates and a LM.
- Agents - extends the capabilities of a LM to use external tools and reasoning, so it can do more than just output text (link).
- RAG - easily build a Retrieval Augmented Generation (RAG) pipeline to work with a LM.
- Chains - core concept for LangChain - the ability to chain sequences of queries, functions, runnables
LangSmith is the LM-Ops counterpart for LangChain that includes functions like:
- Observability - modules to observe and stack trace LM functions.
- Dataset management - create, manage & version datasets
- Evaluation - modules & harnesses for LM application evaluation and inspection
- Administration - create & control organizational access to LMs
- Fine-tuning - use to fine-tune LMs
LangServe is a framework for 1-click deploying LM applications - still in development. Given the use case I’m discussing, seemed worth mentioning.
LlamaIndex
LlamaIndex is a high level package for building LM applications, which include modules for:
- Turning unstructured text data into structured text data.
- Query engines - think information retrieval engine or RAG + LM to generate a response.
- Chat engine - module that supports a stateful chat that remembers past interactions and uses them as context.
- Agents - module that allows the LM combined with external functions or a reasoning loop to perform more complex tasks.
HuggingFace Transformers
Transformers is a sprawling set of packages and libraries from HuggingFace that quite frankly, I cannot possibly describe meaningfully in a blog post. For our purposes, the Transformers package provides high level abstractions that enable users to access:
- Pipelines - Create pipelines for various ML based tasks in various domains including Computer Vision, Audio, Natural Language Processing & Multi-modal models.
- Models - download and use different open-source models from the HuggingFace model repository for different tasks across machine learning and Gen-AI.
- Manage datasets - version, download and share machine learning datasets for a wide variety of tasks across Computer Vision, Audio, Natural Language Processing & Multi-modal models.
- Pre-process data - support for pre-processing data for a wide variety of tasks and types of models - though this is probably the hardest part of the package to navigate in my experience.
- Distributed training - with the Accelerate library
- Fine-tuning - using the Parameter Efficient Fine Tuning library to help fine-tune LMs using various adapters like LoRA, IA3, etc.
Ray from AnyScale
Ray is a all-in-one any-cloud package from AnyScale, that enables the development and productization of deep learning models over distributed systems. It also supports a range of machine learning frameworks, its modules include functionality to manage:
- Distributed ML - lets you run tasks and functions on remote clusters across multiple compute instances.
- Data - specialized for data pre-processing and has support for offline batch inference, with optimization for using both CPUs and GPUs (seems like a good idea in theory).
- Training - primary feature is scalable distributed training and fine-tuning of neural network models using a variety of frameworks (e.g. PyTorch, TensorFlow/Keras, HuggingFace Transformers, Horovod, etc).
- Tuning - enables hyperparameter tuning at scale, with support for a range of machine learning frameworks (PyTortch, TensorFlow/Keras, etc.) and hyperparameter optimization tools.
- Serving - is framework-agnostic toolkit to serve machine learning models built with different frameworks. Also has support for combining multiple models in a multi-stage pipeline.
- Reinforcement Learning - Reinforcement Learning is another area where Ray provides some unique functionality (apart from using distributed systems for machine learning).
TorchTune
TorchTune - is a PyTorch native library for pre-processing data, fine-tuning, exporting or quantizing LMs for inference. I mention TorchTune for completeness.
For a specific guide on fine-tuning Llama 3 with TorchTune & Q-Lora, see this link
In Summary
That’s a 10,000 ft view of these different frameworks I’ve come across and their capabilities. If you are new to this space - expect to spend a lot of time familiarizing yourself with the theory behind all of these capabilities, the operational aspects (stack, integrations, etc) and using the APIs as needed. Note that Ray or Transformers are more general purpose machine learning frameworks, while LangChain, TorchTune and LlamaIndex are specific to LMs.
I’m planning 2 more posts in a similar vein - the first about fine-tuning techniques, RAG and when they are useful or appropriate; and second about cloud support & pricing for different LMs and LM-based applications. This is a rapidly changing space with a ton of new vendors and offerings, so trying to cut through the noise should be interesting.