Having helped organizations build their MLOps strategy and infrastructure, I’m very familiar with the what, why & how of MLOps. Our teams were facing challenges with scaling our machine learning algorithms around 2017-2018, that is when we turned our attention to a new term - MLOps or machine learning operations.
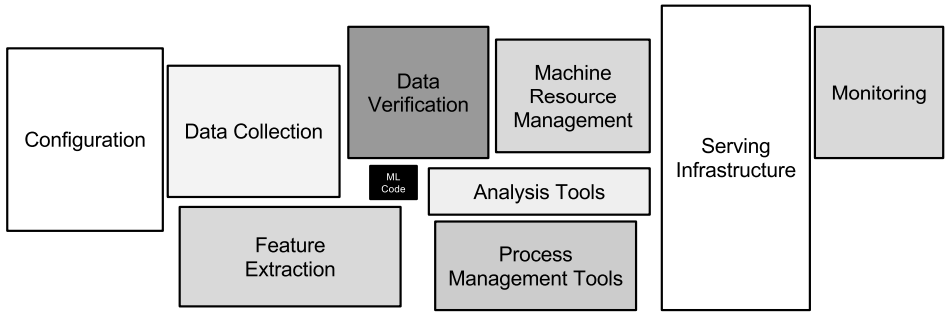
Why MLOps
Lets start with the why first. The diagram is from an influential paper from a group in Google who pointed out that in order to put machine learning systems in production, the actual ML code make up a small percentage of the system. The infrastructure surrounding that ML code, that helps run, monitor and maintain the ML code is far larger.
MLOps comes from the need for systems to help coordinate the operations of that surrounding infrastructure with the ML code.
Benefits of MLOps
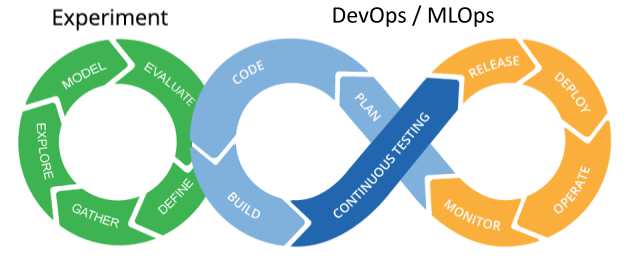
Using MLOps comes with some additional benefits when putting AI-ML algorithms into production, similar to the benefits from dev-ops. Primarily, it enables teams to be agile in their experimentation vs deployment cycles. Done correctly, it becomes easty to take AI-ML models from the experiment / research phase and seamlessly and regularly - build, test, release and deploy models into production.
Another important benefit is the ability to monitor AI-ML algorithms across environments. The raison d’être for these systems is to catch anomalies in data, models and integrations in different environments well before they get to production.
My experiences
I gave a talk on MLOps in 2019 at the Philly DataJawn. The response from the audience then was notable as is the continued relevancy of the topic and learnings from then. My datajawn presentation is linked here.